
2016年8月 ウェブ版第1.05版
NPO日本医薬品安全性研究ユニット
近年、日本でもデータベース研究が実施される機会が増えつつある。薬などの曝露とアウトカムの関連などを研究するデータベース研究の信頼性を上げるためには、アウトカムなどに関するバリデーション研究の実施が望まれる。
しかし、日本ではデータのリンケージが厳しく制限されており、実施可能なバリデーション研究の方法は限られている。数少ない方法の一つとして考えられるのは、各病院や診療所ごとにそこから発行されたレセプトデータを用いて、レセプトから得られる情報を用いた定義に合致するアウトカムなどが発生した(または疾患を有する)当該病院の入院・外来患者を特定し、カルテなどの原資料にさかのぼって、あるいは、院内のがん登録など、より正確な情報と照らし合わせ、定義の妥当性を評価する方法である。
その際、まず求められるのが、各医療機関内で行う、その医療機関から発行されたレセプトデータを匿名化する作業である。レセプトデータの内容は、どのパソコンでも標準で搭載されている「メモ帳」などで誰でも容易に見ることができ、患者氏名は日本語で与えられている。病名には日本語で記載されているものもあり、コード化された病名についても、それが何を意味するかは、インターネット上に公開されている情報から知ることは容易である。
このような情報の匿名化作業を第三者に依頼して実施することは、個人情報保護の観点から問題となりうる。しかし、匿名化作業を実施するための十分なリソースを院内にもたない医療機関も少なくないと考えられる。本マニュアルは匿名化作業の手順を示すとともに、無料のソフトウェアによる匿名化の方法を示すことによって匿名化作業のハードルを下げることを目的として作成された。
作成にあたっては、これまで日本から公表された唯一のバリデーション研究(Biol Pharm Bull, 2015. 38: 53-57)の筆頭著者の佐藤泉美先生(京都大学・薬剤疫学)から提供を受けた当該研究においてレセプトデータの匿名化作業に使用したSASプログラムを参考にした。また、平成28年に、東京都内のある診療所で実際に発行された電子レセプト情報も参考にした。
診療所以外の電子レセプトの処理などにあたっては、本マニュアルでは十分対応できないことも起こりうると考えられる。また、電子レセプトのフォーマットは決められているとはいえ、いわゆる「レセコンメーカー」によって、作成される電子レセプトに何らかの違いが存在し、特別な対応を要する問題が起こる可能性は否定できない。その他、病院ごとに情報入力の方法が異なり、この差が本マニュアルでは対応をできない問題を起こす可能性も否定できない。問題点に関しては指摘を受け、本マニュアルの改良につなげ、日本におけるデータベース研究に貢献していきたい。
また、特定の医療機関から発行されたレセプト情報には
は含まれておらず、単一医療機関から発行されたレセプトデータからレセプトに関するデータベースのデータを完全に「再現」することは不可能である。院外処方される薬がバリデーション研究で重要である、などの場合には院内に残されている薬のオーダーの記録などからレセプトデータベースではどのような値が得られるかを推測するなどの努力が必要である。いずれにしても、完全な「再現」は困難であるとの限界を十分認識した上で研究を実施する必要がある。
病院・診療所などから提出される電子レセプトの仕様については、社会保険診療報酬支払基金ウェブサイトの「電子レセプトの作成」ページなどから得ることができる。
医療機関から請求される医療費は、社会保険診療報酬支払基金と国民健康保険団体連合会によって支払われるため、医療費の請求書である電子レセプトも社会保険(社保)と国民保険(国保)に分けて別々に作成される。また、DPC病院では、DPCレセプトと医科レセプトが作成される。
本マニュアルではWindows用の無料ソフトウェアSmoothCSVを利用する。
SASやMicrosoft Accessなどを使う手順もありうるが、いずれのソフトも有料であり、また、無料のソフトウェアの中でもSmoothCSVは、もともとCSVファイルとして作成されるレセプトファイルをCSVファイルのまま扱えるので、特定形式のファイルとして読み込む手間が不要である。また、大きなファイルを高速に処理できるソフトと評価されているほか、マクロ(JavaScript)とSQLが利用可能な点からもSmoothCSVはレセプトの匿名化処理に有用と考えられる。
本マニュアルにおける手順では、研究期間に発行されたレセプトデータをレセプトの種類ごと(例:社保/国保ごと)に匿名化する。
ファイルの統合:SmoothCSVのSQLを使う。SmoothCSVを立ち上げ、「ツール→SQL実行」で示されるSQL編集画面に以下のコード(ファイルのパスについては適宜修正)を入力し、実行する(コード記載欄の左上の緑色の矢印ボタン を押す)。
を押す)。
以下のSQLを実行する。本マニュアルではSQLを実行する時は、ファイルは閉じた状態で(開かずに)行うものとする。
注)②で説明する通りSQL実行時にテーブルを閉じることは必須ではないが、本マニュアルではSQL実行時にはファイルは閉じた状態で実行、マクロ実行時にはファイルを開いた状態で行うことを基本とする。
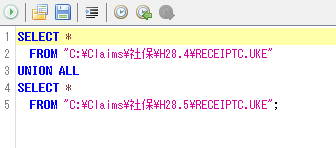
上の例では2ヵ月分が統合されるが、"UNION ALL"で必要な数の(全研究期間の)ファイルを結合することができる。上に示した図にある通り、マクロ記載欄ではコードが青、ピンク、黒などに色分けされて表示される。コードが不適切であることが、コードの色から判明することもある。
SQLを実行し、結果がでると「新しいタブに表示する」「ファイルに出力する」の選択を求めるダイアログボックスが開く。「新しいタブに表示する」を選択する。
そのまま作業を続行することも可能だが、ここで一度保存してもよい。保存しない場合には、「新しいタブに表示する」を選択後に示されるテーブルの1列目をハイライトし「データ→列操作→列を挿入」で空白の列を左端に作成する。一度保存し、あらためて「ファイル→開く」で保存したテーブルを開き、その1列目をハイライトし 「データ→列操作→列を挿入」で空白の列を左端に作成してもよい。
以下のマクロを実行する。
マクロを実行する時には、ファイル(テーブル)は開いた状態で実行する。開かれているテーブルにマクロで指示したことが行われる。以下では空白の第1列目に番号が書き込まれる。
テーブルを開いたまま、「マクロ→編集」を選択すると開く「マクロを新規作成しますか。」のダイアログボックスに「はい」。 表示される編集画面(「マクロを編集」)に以下のマクロ(SmoothCSVのオンラインマニュアルのマクロに関するページにサンプルとして挙げられている)をペーストする。
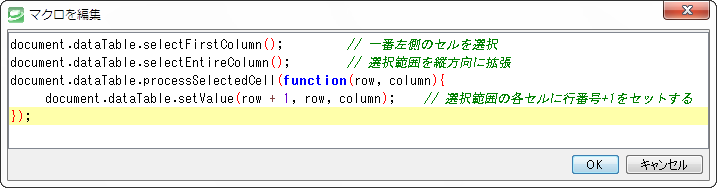
SQLと同様、マクロもコードは色別に表示される。
「マクロを編集」の下にある「OK」ボタンを押すと、編集画面が閉じる。
編集画面を閉じてから「マクロ→再生」によりマクロが実行され、空白だった1列目に通番が付番される。
「ファイル→名前をつけて保存」で適当な名前(例:C:¥Claims¥社保¥Combined¥ClaimDataOriginal.csv)をつけて保存。
(保存の際、「ファイルのタイプ」が「csvファイル(*.csv)」であることを確認して保存。)
次にテーブルを閉じて(「ファイル→閉じる」)以下のSQLを実行する。
①で作成された行番号が付番されたファイルから、[Ⅰ]行番号(1列目)、レセプト番号(3列目)、診療年月(5列目)、生年月日(8列目)、性(7列目 1男、2女)、カルテ番号(15列目)をもつ個人IDファイルと[Ⅱ]カルテ番号(15列目)のみのファイルを抽出する。
[Ⅰ]「ツール→SQL実行」で示されるマクロ編集画面に以下のコード(パスについては適宜修正)を入力、コード記載欄の左上の緑色の矢印ボタンを押し、実行。
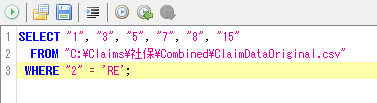
「新しいタブに表示する」「ファイルに出力する」の選択が求められたら「新しいタブに表示する」を選択して、内容を確認する。
作成されるファイルは6列からなり、左から順に以下の内容を持つ。
確認後、「ファイル→名前をつけて保存」で保存する。たとえば、"C:¥Claims¥社保¥Combined¥IDFile.csv"として保存する。
注)①で言及した通り、SQL実行時にテーブルを閉じることは必須ではなく、たとえば、上記"C:¥Claims¥社保¥Combined¥ClaimDataOriginal.csv"を開いた状態で
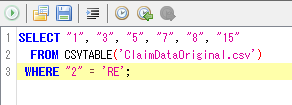
を実行しても同様の結果がえられるが、本マニュアルではSQLを実行する際にはファイルは開かずに実行する。
上記ファイル("C:¥Claims¥社保¥Combined¥IDFile.csv")については「テーブルを閉じる」(「ファイル→閉じる」)。
[Ⅱ]「ツール→SQL実行」で表示されるコード記述部分に以下のコード(ファイルのパスについては適宜修正)を入力、実行する(コード記載欄の左上の緑色の矢印ボタンを押す)。
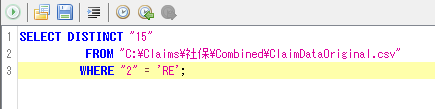
"DISTINCT"が含まれているので、カルテ番号が一意に抽出される。
適当な名称(例:"C:¥Claims¥社保¥Combined¥IDFile2.csv")で保存する。
次もSQLを実行するのでテーブルを閉じる(「ファイル→閉じる」)。
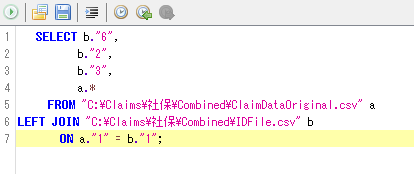
①で作成したファイル(SQL内では"a"テーブル)の左側に"C:¥Claims¥国保¥Combined¥IDFile.csv"("b"テーブル)の6列目(カルテ番号)、2列目(レセプト番号)、3列目(診療年月)を書き足す。以下のSQLでは、"a"テーブルの左側に3列が新たに追加され、このうち、識別情報が"RE"の対応する行"についてのみ(行番号<a."1"とb."1">が一致する場合のみ)、"b"テーブルのカルテ番号、レセプト番号、診療年月が記載される。
<注:元のレセプトファイルにはすでに①で行番号が付加されており、本操作で、元のレセプトの左側に合計4列が追加されることになる。>
カルテ番号は後の段階(⑥)で研究用IDと置き換えられる(保険者の記号・番号や氏名は転職や結婚などで変化しうるので、カルテ番号を個人IDと考える)。
レセプト番号は、医療機関内で電子レセを作成する段階で作られる番号であり、当該施設の当該月のレセプトに順番に与えられる(通番)。同一の患者であっても同一月に2つ以上のレセプトが発行されれば、レセプト番号は異なる。社保、国保などのレセの種別+診療年月+レセプト番号によって、レセプトが一意に指定できるので、「診療年月+レセプト番号」はレセプトIDとして機能する。
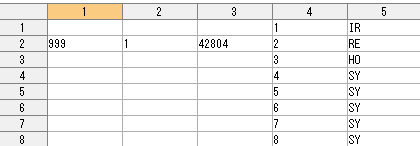
以下に作成されたテーブルの最上部、左5列を示す。1列目の"999"が(架空の)カルテ番号であり、2列目"1"はレセプト番号、3列目"42804"は診療月(平成(4)、28年(28)、4月(04)。4列目は①で新たに与えた行番号、5列目が"RE"などのレコード識別情報)。
ここでファイルを保存(たとえば"C:¥Claims¥社保¥Combined¥ClaimData_temp.csv")してもよいが、この段階のファイルの保存は必須ではなく、このまま以下の④に進むことでもよい。④のマクロはテーブルを開いた状態で実行する。
上記③で作成された"C:¥Claims¥社保¥Combined¥ ClaimData_temp.csv"をSmoothCSVで開き(あるいは③のSQLの結果作成されたテーブルを開いた後、直接)、以下のマクロを実行(「マクロ→編集」で開くマクロ編集ページに以下のコードを入力、「OK」により編集画面を閉じ、「マクロ→再生」)する。1から3列が空欄の行に必要情報を書き足す。
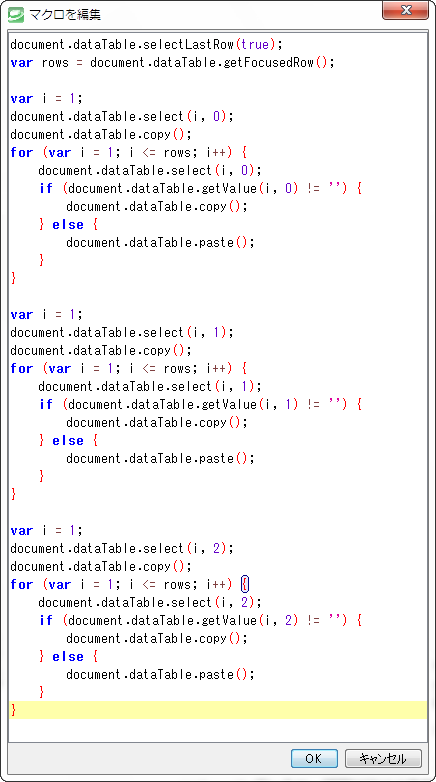
マクロ実行後のテーブルの最上部、左5列を示す。
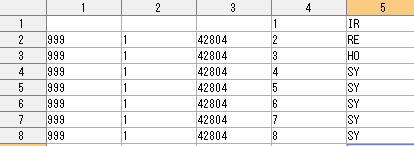
1から3列目の空白だった行に、5列が"RE"の行(第2行)にあったカルテ番号、レセプト番号、診療年月が同一レセプトの全レコードにコピーペーストされる。結果を「ファイル→名前をつけて保存」により保存(例:"C:¥Claims¥国保¥Combined¥ClaimData_Temp2.csv")。 次の⑤に移行する前に、上記①から④の作業を全ての種類のレセプト(社保、国保、DPC……)について実施する。次の⑤では全ての種類のレセプトに関する②の[Ⅱ]で作成された複数の" IDFile2"を結合する。
研究期間の全種類のレセプトから上記②[Ⅱ]で抽出した"IDFile2.csv"を以下のように、"UNION"で上下方向に結びつける(UNION ALLではなくUNIONを使うことでダブりが省かれる)。本マニュアルでは、匿名化処理はレセプトの種類(国保/社保など)ごとに実施することを想定しているが、研究用IDは全種類のレセプトにおいて一意の番号として作成する。カルテ番号が同一の患者が研究期間内に国保→社保または社保→国保など、異なる種類のレセプトに移行することがあり得るからである。
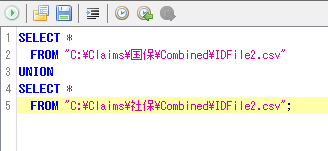
<上記では国保と社保のカルテ番号ファイル2つを結合する。DPCと医科レセが発行されているDPC病院などではより多くの種類のレセプトが発行されるが、いずれにしても、全種類のレセプトから作成した"IDFile2"を"UNION"で結合する>
実行後「新しいタブに表示する」を選んで表示されたテーブル(列数=1)の列をハイライトし、「データ→列操作→列を挿入」。 さらに①と同じ以下のマクロを実行。
このマクロにより、新たに挿入した空白の列に1から順番に付番されるので、これを研究用IDとして使用する。 作成されたファイルは適切な名称(たとえば" C:¥Claims¥IDs¥ID対応表.csv")で保存。
対応表は以下の⑥で、カルテ番号を研究用IDと置き換えるのに使用するが、解析担当者が抽出した研究用IDに対応するカルテ番号の患者を特定する際にも使用するので、匿名化作業が終了後もバリデーション研究が終了するまで医療機関内で保管することが必要。
ファイル→閉じる
上記⑤では研究期間に発行された全種類のレセプト(社保、国保、・・)から抽出されたIDFile2.csvを操作したが、ここから、また特定の種類のファイル(例:社保)の操作にもどる。
カルテ番号が1列目に含まれる④で作成されたファイルに研究用IDを与える。
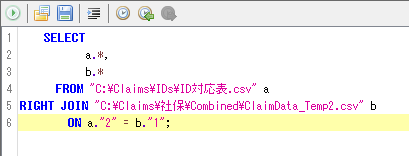
実行後「新しいタブに表示する」を選んでテーブルを表示。1列目(37)は研究用ID、2列目と3列目はカルテ番号。
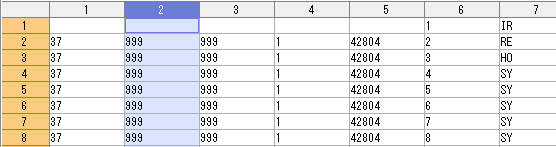
カルテ番号(999)が示されている2列目と3列目をそれぞれハイライトし、「データ→列操作→列を削除」。
カルテ番号を削除後、適切な名前(例:C:¥Claims¥社保¥Combined¥ClaimData_Temp3.csv)をつけて保存。研究用IDは1列目に示される。
ファイル→閉じる。
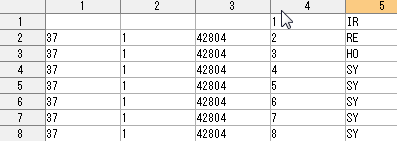
上記⑥で、第1列に示されていたカルテ番号は、研究用IDに置き換えられたが、患者ID情報が含まれる"RE"、診療機関の情報が含まれる"IR"、保険者と保険者番号の情報が含まれる"HO"、公費補助に関連する個人情報が含まれる"KO"から始まるレコードには個人情報が含まれており、適宜削除する。
結果を適当な名称で保存(例 "C:¥Claims¥社保¥Final¥社保Main.csv")。 このファイルには、薬、傷病名、診療行為などに関する情報が含まれている。このまま解析担当者に渡すことも許されうる程度に匿名化されたファイルである。
Mainのファイルから除かれたレコードのうち、医療機関の情報(IR)に含まれる情報は通常不要と考えられる。
それ以外では、たとえばレセプト共通レコード(RE)の「レセプト種別」(4ケタ目が奇数なら入院、偶数なら入院外)、「入院年月日」、保険者レコード(HO)や公費レコード(KO)の「診療実日数」などが必要となることは多いと考えられる。ただし、氏名なども含まれているため、これらを除く作業が必要である。
"RE":氏名(5)、生年月日(7)を除く
<生年月日については、月日の情報を削除し、生まれた「年」のみとするオプションも考慮されると思われるので、REファイルからは生年月日を除去し、⑧に記述する各研究用IDに対応する生年月日または生年のみのファイルを別途作成。>
適当な名称(例:C:¥Claims¥国保¥Combined¥RE_temp.csv)で保存。
ファイル→閉じる。
次いで氏名と生年月日を削除するファイルを作成。
上記では、本手順作で参考にした平成28年の診療所からのレセプトは36列からなっていたため、最大の列が"40"(左に新たに4列を足したので合計36+4=40列)となっているが、本作業を実施する前に、対象のファイル(例: C:¥Claims¥社保¥Combined¥RE_temp.csv)を開いて、列数を確認しておくことが望ましい。
また、左に4列足したファイルでは「氏名」が第9列に、「生年月日」が第11列に位置するので、上記のSQLではこの情報を削除したファイルを新たに作成している。作成後、氏名と生年月日が削除されていることを確認する。
共通レコードに関する匿名ファイルとして適当な名称(例:"C:¥Claims¥社保¥Final¥社保RE.csv")をつけて保存。
「診療実日数」などが含まれるので、必要となることがあると考えられる。最低限以下の項目の削除が必要。(他にも、たとえば「合計点数」は不要、と判断されるような場合はありうる。)
"HO":保険者番号(2)、被保険者証(手帳)等の記号(3)、被保険者証(手帳)等の番号(4)。
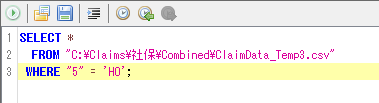
適当な名称(例:C:¥Claims¥社保¥Combined¥HO_temp.csv)で保存。
ファイル→閉じる。
以下では、保険者番号(2)、被保険者証(手帳)等の記号(3)の情報は対象ファイル(例:C:¥Claims¥社保¥Combined¥ClaimData_Temp3.csv)の6, 7, 8列にあることが前提になっているが、実施前にファイルを開き、確認しておくことが望ましい。また、最大列数(以下では最大40列)も確認しておくことが望ましい。

保険者レコードに関する匿名ファイルとして適当な名称(例:"C:¥Claims¥国保¥Final¥社保HO.csv")をつけて保存
「診療実日数」などが含まれるので、必要となることがあると考えられる。最低限以下の削除が必要。(他にも、たとえば「合計点数」や「食事療養・生活療養」の「合計金額」などが不要と判断されるような場合はありうる。)
"KO":負担者番号(2)、受給者番号(3)
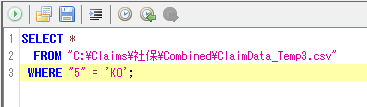
適当な名称(例:C:¥Claims¥国保¥Combined¥KO_temp.csv)で保存。
ファイル→閉じる。

公費レコードに関する匿名ファイルとして適当な名称(例:"C:¥Claims¥国保¥Final¥国保KO.csv")をつけて保存。
②[Ⅰ]で作成したIDFile.csvのうち、性別、生年月日、カルテ番号を一つにまとめる。
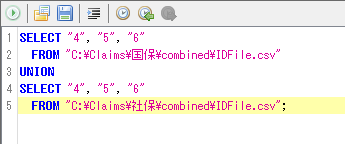
上記では、国保と社保に関する二つのIDFileを結合しているが、DPCと医科レセプトについて別々にIDFileを作成したなどの場合は、全てのIDFileをUNIONで結合する。
作成後、適当な名前(例:C:¥Claims¥IDs¥DemographicInfoTemp.csv)で保存。
ファイル→閉じる。
カルテ番号を研究用IDで置き換える。
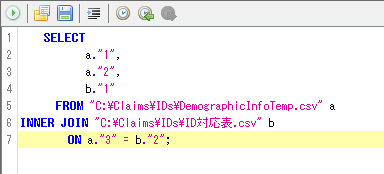
作成後、適当な名前(例:C:¥Claims¥IDs¥DemographicInfo.csv)で保存。
以下を実行すれば、生年月日から生年だけの情報が抽出される。
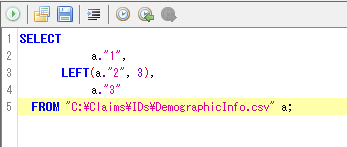
適当な名称(例:C:¥Claims¥FinalDemo¥DemoInfo.csv)をつけて保存。
上記のうち、生年と性に関するファイル(⑧で作成)
(1) C:¥Claims¥FinalDemo¥DemoInfo.csv
国保、社保などのMainとRE、KO、HOファイル(⑦で作成)
例:
などが、匿名化されたレセプトファイルである。
<以上>